|
Learning Patterns
Carlos C. Rodríguez
https://omega0.xyz/omega8008/
Set up
We assume labeled data X Î Rd with label Y Î {0,1}.
For example X=x could be the vector of pixels of a digital image of a human
face and Y=1 may mean that x is the face of a woman instead of a man.
The random vector (X,Y) has distribution specified by, for example,
a probability measure m for X and the regression function h(x)
of Y on X. We have,
and
Clearly, by the sum and product rules of probability, we have
|
P{(X,Y) Î C} = |
ó
ő
|
C0
|
(1-h(x)) m(dx) + |
ó
ő
|
C1
|
h(x) m(dx) |
|
where C0 contains all the x's such that (x,0) Î C.
The joint distribution of (X,Y) can be specified in other ways.
Instead of picking first x according to m and then flipping a coin
with probability h(x) to determine the label, we could also
do it backwards.
First choose a label with (prior) probability P{Y=1} = p and then
choose x with density (assuming there is one) f0 or f1 depending
on the previously generated label y. Hence, for y Î {0,1}
|
P{X Î A | Y=y} = |
ó
ő
|
A
|
fy(x) dx |
|
By conditioning of Y we obtain,
|
P{X Î A} = (1-p) |
ó
ő
|
A
|
f0(x) dx + p |
ó
ő
|
A
|
f1(x) dx = |
ó
ő
|
A
|
m(dx) |
|
Thus, if m has a density f(x) = m(dx)/dx it must be a mixture,
|
f(x) = (1-p) f0(x) + pf1(x) |
|
Also, by the holy theorem,
|
h(x) = P{Y=1 | X=x} = |
f1(x)p
f(x)
|
|
|
The Bayes Classifier
A classifier is a map d: Rd ® {0,1} that assigns
0-1 labels to data vectors x Î Rd. The quality of a classifier
d is measured by its risk R(d) which is simply its
probability of error,
The Bayes rule is the classifier d* with smallest possible risk,
so that for all d,
We call R*=R(d*) the Bayes risk. It provides a measure of
difficulty for the pattern recognition task at hand. It is a characteristic
of the joint distribution of (X,Y).
A standard result of statistical decision theory is that the Bayes rule for
the all-nothing (i.e. 0-1) loss function is the mode of the posterior
distribution. Thus, d*(x) = 1[h(x) > 1/2].
Here is an easy proof for the special case of pattern recognition.
Let A(d) = {x : d(x) = 1}. Since f1 is a density
that integrates to 1, we have:
|
R(d) = (1-p) |
ó
ő
|
A(d)
|
f0(x) dx + p(1 - |
ó
ő
|
A(d)
|
f1(x) dx) |
|
Which can be written as,
|
R(d) = p+ |
ó
ő
|
[(1-p) f0(x) - pf1(x)] 1A(d)(x) dx |
|
Notice that the rule claimed to be Bayes, assigns 1 when
h(x) > 1/2 and this is equivalent to require the expression in
square brackets above to be negative.
Now denote by Q(x,d) the function that is being integrated above
and show that for all x Î Rd, Q(x,d*) Ł Q(x,d)
(just consider each of the four cases of x in or outside A(d) and
A(d*) separately). It then follows, by the last equation above
and the monotonicity of integrals, that d* has the smallest
possible probability of error and so it is the Bayes rule as claimed.
An Example
To make things concrete consider the simple case of deciding wether an
observed real number x was generated by a gaussian with mean m0
and variance 1 or a gaussian with mean m1 and variance 1, and the two
choices are considered a priori equally likely (see figure).
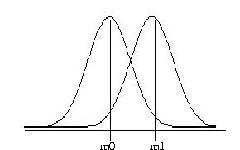 We want to compute the Bayes rule when the distribution of (X,Y)
is characterized by p = 1/2 and fy = N(my,1).
For this case,
We want to compute the Bayes rule when the distribution of (X,Y)
is characterized by p = 1/2 and fy = N(my,1).
For this case,
|
A(d*) = { x : f0(x) < f1(x) } = { x : |
- (x-m0)2
2
|
< |
- (x-m1)2
2
|
} |
|
and simplifies to,
|
A(d*) = { x : |x-m1| < |x-m0| } |
|
This shows that the best rule is to choose the distribution with mean
closest to the observation x.
If we assume that m0 < m1 and let m=(m0+m1)/2 be the middle
point, then the Bayes risk R* is,
|
R* = |
1
2
|
|
ó
ő
|
Ą
m
|
j(x-m0) dx + |
1
2
|
|
ó
ő
|
m
-Ą
|
j(x-m1) dx |
|
By letting z=x-m0 in the first integral, z=x-m1 in the second and
defining 2a=(m1-m0) we obtain a much simpler form,
depending only on the separation between the two means. Here are some values,
| |m1-m0| | R* |
| 0.1 | 0.480 |
| 0.5 | 0.401 |
| 1.0 | 0.309 |
| 2.0 | 0.159 |
| 4.0 | 0.023 |
| 6.0 | 0.001 |
Learning Patterns from a Teacher
If we knew the distribution of (X,Y) we could compute d*, the
Bayes rule, as shown above.
Unfortunately, we rearly know the distribution of (X,Y). This creates
two problems. First, we cannot directly use d* since it depends
on the parameters of the unknown distribution of (X,Y). We need to know
either the sign of (h(x) - 1/2) or the sign of
[(1-p)f0(x)-pf1(x)].
Second, we can not even evaluate the risk R(d) of any classifier
d for that also depends on the unknown distribution of (X,Y).
But if we have available n independent observations
(X1,Y1), (X2,Y2),Ľ, (Xn,Yn) of the vector
(X,Y) then we could use them to estimate the missing distribution
of (X,Y) with the empirical distribution based on the observations.
This could be interpreted as past data that was labeled by a reliable
teacher.
Thus, we could approximate the true probability P{(X,Y) Î C} with
the observed frequency given by the empirical measure nn,
|
nn(C) = |
1
n
|
|
n
ĺ
i=i
|
1[(Xi,Yi) Î C] |
|
The true risk R(d), for a given classifier d,
is estimated from the observed data with the empirical risk,
|
|
^
R
|
n
|
(d) = |
1
n
|
|
n
ĺ
i=1
|
1[d(Xi) ą Yi] |
|
There is then the possibility of evaluating the quality of a d
with its observed frequency of errors [^R]n on the available
data Dn=(X1,Y1, Ľ, Xn,Yn). But we should always
keep in mind that this performance is different for different data
sequences. A classifier that is built from given data Dn has as
its true risk,
|
Rn = P{ dn(X;Dn) ą Y | Dn } |
|
Consistency
It is desirable to be able to quantify not just how good a classifier
is on a fix data sequence Dn but to also know how a given
classification method or rule behaves on most data sequences.
In particular the notion of a consistent sequence {dn}
of classifiers is simply the requirement that,
|
E Rn = P{ dn(X;Dn) ą Y } ® R* as n® Ą. |
|
A classification rule may be consistent for some distributions of (X,Y)
but not for others. If however it is consistent for all of them we say that
it is universally consistent. Are there any known universally
consistent rules? Yes! for example the k-nearest neighbor rule (knn for
short) is one of them. The knn is simply the rule that assigns to x the most
common observed label among its knn's (in any metric topologically
equivalent to the euclidean). Universal consistency for the knn is achieved
only when k=k(n) is such that k® Ą and k/n ®0 as n® Ą. These are the good news. The bad news: the
convergence can be arbitrarily slow! Consistent rules with a given rate
of convergence for all distributions of (X,Y) do not exist. This is
interesting. On the one hand we know that given enough independent examples
it is possible to get arbitrarily close to the performance of the
Bayes rule. On the other hand it may take arbitrarily long for that to
happen.
There are two ways out of this impasse. Use prior information to
constraint the possible probability distributions for (X,Y) or change
the target R* by considering only a subclass C of classifiers.
We take the second route first and show that there are classes C
that provide universal rates of convergence to the best dC*
for that class, i.e.,
|
R(dC*) Ł R(d) for all d Î C |
|
Empirical Risk Minimization
Let us assume that we have data Dn as above from where we can
estimate the true risk of a classifier d by using the observed frequency
of errors on Dn, i.e., by its empirical risk.
Let dn* be the classifier that minimizes the empirical risk
over a given class C of rules, i.e.,
|
|
^
R
|
n
|
(dn*) Ł |
^
R
|
n
|
(d) for all d Î C |
|
We would like to know what kinds of classes C allow universal empirical
learning, in the sense that for all distributions of (X,Y),
It is intuitively clear that what's needed is some kind of constraint on the
"size" (a better term would be capacity) of C.
For example if C contains all possible
classification functions, then no matter what the sequence Dn is,
we can always find a function in this class that fits the data perfectly.
However we also feel intuitively that such a rule will over fit the observed
data and it will show poor performance on sequences other than the
observed Dn, i.e. we expect such rule to have poor generalization power.
This intuitive reasoning will be rigorously confirmed by means of the
celebrated Vapnik-Chervonenkis theory.
We first notice the following simple result:
Lemma 1
|
R(dn*) - |
inf
d Î C
|
R(d) Ł 2 |
sup
d Î C
|
| |
^
R
|
n
|
(d) - R(d) | |
|
and
|
| |
^
R
|
(dn*) - R(dn*) | Ł |
sup
d Î C
|
| |
^
R
|
n
|
(d) - R(d) | |
|
Proof:
|
R(dn*) - |
inf
d Î C
|
R(d) = R(dn*) - |
^
R
|
(dn*) + |
^
R
|
(dn*) - |
inf
d Î C
|
R(d) |
|
|
Ł |
sup
d Î C
|
| R(d)- |
^
R
|
n
|
(d) | + |
sup
d Î C
|
| |
^
R
|
n
|
(d) - R(d) | |
|
The second part is trivial.
The above lemma shows that in order to achieve universal consistency on a given
class, it is sufficient for the supremum appearing on the rhs of the
inequalities to go to zero with probability 1, i.e., all we need to show
is strong uniform convergence, over the given class, of empirical error
to the true error.
File translated from
TEX
by
TTH,
version 3.63.
On 19 Sep 2004, 12:06.
|