Lecture VI
An Introduction to Markov Chain Monte Carlo

Lecture VI
Lecture VI
Abstract
Neural Networks as a way to specify nonparametric regression and
classification models.
Feed Forward Neural Nets Models
Feed forward Neural Nets are also known as multilayer perceptrons or
backpropagation networks. The figure shows a network with a layer of 4 hidden
units.
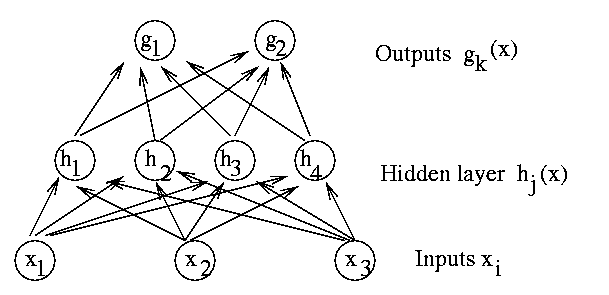
Figure 1: A Feed Forward Network
The outputs are computed from the following formulas,
where {aj},{bk},{uij},{vjk} are the parameters of the
network. The parameters with one index are known as biases and those with two
indeces are known as weights. We assume that x = (x1,¼,xd) Î Rd, h(x) = (h1(x),¼,hl(x)) Î Rl, g(x) = (g1(x),¼,gp(x)) Î Rp. The hyperbolic tangent,
|
tanh(z) = |
sinh(z)
cosh(z)
|
= |
ez-e-z
ez+e-z
|
= |
1-e-2z
1+e-2z
|
|
|
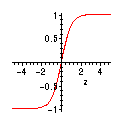
Figure 2: Hyperbolic Tangent
is an example of a sigmoid function. A sigmoid is a non-linear function,
s(z), that goes through the origin, approaches +1 as z®¥
and approaches -1 as z® -¥.
It is known since 1989 (only) that as the number of hidden units increases,
any function defined on a compact set can be approximated by linear
combinations of sigmoids.
Multilayer perceptrons are often used as flexible models for nonparametric
regression and classification. Given data,
|
(x(1),y(1)), (x(2),y(2)),¼, (x(n),y(n)) |
|
with,
where
|
e(1),e(2),¼,e(n) are iid with Ee(k) = 0 |
|
Hence, the g is the regression of y on x, i.e.,
|
E(y | x,q) = g(x,q) with q Î Q |
|
The multilayer perceptrons provide a practical way to define the functions
g with high dimensional parameter spaces Q. We take
q = { {aj},{bk},{uij},{vjk} }. The objective is
to find the predictive distribution of a new target vector y, given the
examples D = ((x(1),y(1)), (x(2),y(2)),¼,(x(n),y(n))) and the new vector of inputs x, i.e.,
|
f(y | x, D) = |
ó
õ
|
f(y | x, q) p(q| D) dq |
|
Under the assumption of quadratic loss, the best guess for y will be its
mean,
|
|
^
y
|
= E(y | x,D) = |
ó
õ
|
g(x,q) p(q|D) dq |
|
These estimates can be approximated by MCMC by sampling
q(1),¼,q(N) from the posterior
and then computing empirical averages,
|
|
^
y
|
N
|
= |
1
N
|
|
N
å
j = 1
|
g(x,q(j)) |
|
Useful Priors on Feed Forward Networks
In the absence of specific information, the following assumptions about the
prior p(q) are reasonable,
- The components of q are independent and symmetric about 0.
- Parameters of the same kind have the same a priori distributions, i.e.,
With these assumptions if varp(vjk) = l-1s2v < ¥ then by
the Central Limit Theorem, as l® ¥ the prior on the output
units converges to a Gaussian process. Gaussian processess are characterized
by their covariance functions and they are often considered innadequate for
modeling complex inter-dependence of the outputs. To avoid the Gaussian trap,
it is convenient to use a priori distributions for the components of q
that have infinite variance.
A practical choice (used by Neal) is to take,
|
vjk as t-distribution µ |
æ
ç
è
|
1 + |
vjk2
asv2
|
ö
÷
ø
|
-(a+1)/2
|
with 0 < a < 2 |
|
Furthermore, if the we take sv = wv l-1/a then the
resulting prior will converge as l®¥ to a symmetric stable
process of index a.
Recall that Z1,Z2,¼,Zn iid with distribution symmetric about
0 are said to be stable of index a if
|
|
Z1 + ¼+ Zn
n1/a
|
has the same law as Z1 |
|
A distribution is said to be in the domain of attraction of a stable law
if properly normalized sums of independent observations from this
distribution, converge in law to a stable distribution. Hence, distributions
with finite variance are in the domain of attraction of the Gaussians. It is
also well known that distributions with tails going to zero as
|x|-(a+1) as |x|®¥ are in the domain of attraction
of stable laws of index a which justifies the choice of t-dist above.
Postulating an Energy for the Net
An alternative approach without priors (apparently...) is to postulate
directly and Energy function for the network, e. g,
|
E(q,g) = |
1
n
|
|
n
å
k = 1
|
L(y(k),g(x(k),q)) + g||q||2 |
|
where L(y,z) is the assumed loss when we estimate y with z. Typical
choices are L(y,z) = R(||y-z||) for some nondecreasing function R and
some norm ||·||. Then choose q to minimize this Energy function.
Often, the smoothness parameter g > 0 is chosen by Cross-Validation or
by plain trial and error.
For complicated multi modal energy functions, a combination of simulated
annealing with a classical gradient method (such as conjugate gradients) have
been the most successful.
File translated from TEX by TTH, version 2.32.
On 5 Jul 1999, 22:59.