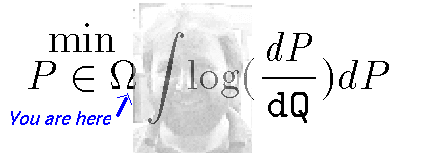
So what can be done with a Markov chain monte carlo method such us Metropolis? The simple answer is: A Lot! Computation of integrals, simulation of complex probabilistic models, and optimization, are just three general areas with practical applications to virtually all domains of current science and technology. During the last ten years the subject has been continuously picking up momentum at an accelerated rate and there is no sign that this trend will change much, at least in the near future. Check the online preprint service at Bristol or search for ``Monte Carlo'' at Los Alamos xxx.lanl.gov archives. The recent discovery of the Propp and Wilson algorithm, that allows to rigorously determine convergence in some cases, has contributed to raise the expectations even further about the utility of these techniques. The
optimistic futurists are even claiming that we'll be able to achieve immortality (no kidding) in about 40 years!... that's hype.
As simple illustrations of the applicability of MCMC we show general statistical inference and combinatorial optimization.
If we want to represent the amount of truth in a proposition A in the domain of discourse of another proposition B (i.e. given B) with real numbers then these numbers must (modulus re graduation) satisfy the usual rules of probability, i.e. if P(A|B) denotes the truth in A given B:
From the commutativity of conjunctions (in all domains of discourse) we have,
|
|
|
|
|
Given the likelihood, the prior and the data, the problem of inference reduces to a problem in computing. The computation of the posterior. When we know how to sample from the posterior we know all there is to know about the inference problem (with that likelihood, prior and data). All the quantities necessary for making decisions can be computed (in principle) by MCMC methods. To be able to formalize the problem of making decisions in the face of uncertainty it is convenient to postulate the existence of a loss function that quantifies how much it is assumed to be lost when the true scenario is q and we take action a, i.e.
|
The loss function provides the criteria for choosing the best action. The best action is that which minimizes the expected loss. The MCMC methods come to rescue us here also for we need to solve,
|
A combination of Monte Carlo integration by sampling from the posterior p(q| D) and simulated annealing for the minimization.
In estimation problems q and a belong to the same vector space ( with norm |·|) and loss functions such as the quadratic |q-a|2, the linear |q-a| and the all-nothing -d(q- a) ( Dirac's delta) are used. Notice, that when these loss functions are used the best estimators become the posterior mean (for the quadratic), the posterior median (for the linear in dimension one) and the posterior mode. It is also worth seeing that maximum likelihood estimators are best for the all-nothing loss with p(q) µ 1 (flat prior). So maximum likelihood does use a prior. It is only that sometimes it is the wrong prior!
When, the components of the data vector D = (x1,x2,Ľ,xn) are iid with pdf f(x|q) the predictive distribution for a next observation y = xn+1 is given by,
|
The unknown true image (the theory) can be denoted by q = (q1,Ľ,qM) where qj = 1 if the j-th pixel is on otherwise it is 0. The hypothesis space, i.e. the space of all possible images is finite but big. There are 210,000 ~ 103,000 possible images. We can go superlative here with the usual...
not even if all the atoms of the universe
were personal computers
displaying images from this space
operating day and night
since the time of the big bang!
not even in that case...
not even there you would be able to see a sizable portion of the image space. That is an example of a combinatorial optimization problem.
Let us denote by z = (z1,Ľ,zM) the corrupted image which, together with the prior knowledge of the definition of the problem, is the only thing that we have. A good looking image is obtained by solving,
|
Simulated annealing can be implemented by thinking of the cost function as the energy and running the Metropolis algorithm by picking at random between the following proposal moves:
all the moves are local, affecting only a few pixels, so the change in energy needed for the acceptance probability in the Metropolis algorithm is cheap to compute...
Homework Do it (and get a big A+)! you won't be able to do it in JavaScript though.... I don't think (but please prove me wrong) you may need plain Java for this one.
For example consider the one dimensional kernel estimator with Gaussian kernel and scale parameter h based on iid observations of an unknown pdf f.
|
|
|
It is possible to write down a formula for the posterior mean of h as follows. First, write the likelihood as a sum of products instead of as a product of sums to get,
|
|
|
Notice that there are a total of (n-1)n paths. Typically n ~ 100 so the size of I is of the order of 10200. Huge.
The posterior mean for h, for priors of the form p(h) µ h-(d+1), can be written explicitly as,
|
|
Posterior means for h can be computed very accurately by MCMC for this problem. By using Metropolis to sample path i with probability proportional to a(i) and then computing empirical averages for s(i). We know it works since the smootheness parameters produced by the method give remarkably good reconstructions of the density, much better than the ones obtained by plain cross-validation. Check it out
It works!