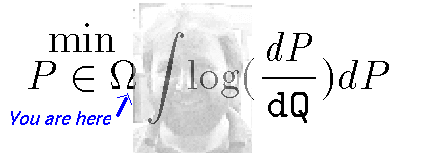
To sample from an arbitrary random vector X Î Rp with pdf f just turn f into a canonical distribution by choosing T and Z(T) and defining an energy function by,
|
|
|
|
|
|
| ||||||||||||||||||||||
{}
X0 Ỳ x0 (arbitrary)
for t = 0,1,2,ỳ
{}
y Ỳ sample from q(·|xt)
u Ỳ unif(0,1)
if u £ min{1,f(y)/f(xt)} then Xt+1 Ỳ y
else Xt+1 Ỳ xt
Example: Javascript implementation of plain vanilla Metropolis for sampling from N(0,1) with
|
|
|
|
|
which is true, since when the min. on one side is 1, the min. on the other side isn't and the denominator cancels with the term outside the parenthesis producing the equality of both sides.
As always, detailed balance is enough to assure that f is the stationary distribution for the chain. But detailed balance is not necessary. It is possible for a chain to have f as its stationary distribution without p(y|x)f(x) = p(x|y)f(y) for all x,y. All that it is needed for stationarity is, (its definition)
|
|
Knowing that f is a stationary distribution for a Markov Chain with transition kernel p(x|y) is not enough to warrant that the chain will eventually sample states according to the density f. It only says that if at some time t the density of Xt is f then it will remain f for all subsequent times since the law of Xt+1 is Tf = f. From the classical fix point theorem of functional analysis we know that if the f's belong to a complete metric space, with distance function d, and the operator T is contractive, i.e.
|
then the iterates f0, T(f0), T(T(f0)),ỳ converge geometrically in the metric of the space to the unique fix point for T, provided that the initial f0 is not too far from the fix point. Notice that,
|
Thus, the Markov Chain is expected to have the fix point as its long-run distribution. As we will see later the conditions of the classic fix point theorem are too restrictive. Under mild regularity conditions on the kernel (e.g. when T is only contractive on the average) a large class of Markov Chains will be geometrically ergodic. More on this theme when we look at convergence theorems...
|
If J Ì I we write x-J the set of all coordinates except those in the set J, i.e. x-J = xI\J. Let I1,I2,ỳ,Im form a partition of I so that x gets separated into m groups,
|
Start the Metropolis-Hastings algorithm from somewhere and suppose that at time t we are visiting state x, then at time t+1 we either remain at x or we go to y by modifying only one of the m components of x, i.e.,
|
The value of k can be chosen at random among {1,2,ỳ,m} or one after another cyclically, in which case to have a homogeneous Markov chain we need to define one iteration only after a full sweep over the set of m components is completed. Choosing the components at random eliminates this problem but may end up, by chance, neglecting some of the components for a long time. An intermediate solution is to randomize the order and then update the components in that order. In all these cases the acceptance probability is the usual Metropolis-Hastings formula but when x differs from y in the k component we have,
|
where qk is the proposal function q for updating component k and ratio f(y)/f(x) is written as the ratio of full conditionals, where,
|
By writing the acceptance probability in this way we can see that the Markov Chain associated to the sequence of updates of component k, with all the other components fix at x-Ik, has the full conditional (defined above) as stationary distribution. Eventually all the components end up sampling from the correct conditionals.
|
In this case the acceptance probability becomes 1 and the Gibbs sampler always accepts the proposal candidates. Gibbs sampling is just a special case of Metropolis. This is the justification to the popular statement: to sample from a joint distribution just sample repeatedly from its one dimensional conditionals given whatever you've seen at the time.
{}
X0 Ỳ x0 (arbitrary)
for t = 0,1,2,ỳ
{}
k Ỳ unif. on {1,2,ỳ,p}
yk Ỳ sample from f(xk|xt-{k})
Xt+1 Ỳ {yk,xt-{k}}
Example: Javascript implementation of Gibbs sampler for generating samples from (X,Y) with one dimensional conditionals given by:
| |||||||||||||||