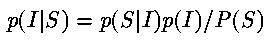 Equation 1
Equation 1 The acquired informative samples are nonuniformly distributed over a uniform grid [1] We seek a solution in the Fourier domain that optimizes some quality criterion while the inverse FFT of the solution is kept compatible with the acquired samples. This approach is similar to that of MEM [2], but our quality criterion is not derived from the entropy of an image. In fact, ours is based on the finding that the histogram of {\em differences} of grey values of adjacent pixels (edges) has approximately Lorentzian shape [3]. This was successfully applied to a real-world human brain scan [1].
Using Bayesian probability theory, we have enhanced the method of Ref. [1]. This allows concurrent handling of noise and ringing. The procedure is applied to each row in the incompletely sampled phase encoding space, after FFT in the acquisition space (i.e., columnwise).
Equation 1
in which I is a row of the image, S the attendant row of samples. p(I|S) is the probability of an image given the samples. p(S|I), the probability of the samples given an image, relates to the noise distribution function. p(I) comprises prior knowledge about the image, e.g., the Lorentzian shape of the histogram mentioned above, and low intensity outside the boundaries of the object. p(S) is usually just a scaling constant, once the samples have been acquired [4].
The task is to find the image that maximises p(I|S). Assuming Gaussian measurement noise with standard deviation \sigma, and a unitary FFT matrix, one finds for each row
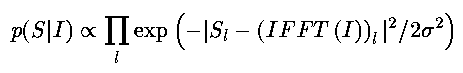 Equation 2
Equation 2
the index l pertaining to the informative samples alluded to above. The prior knowledge term p(I) can be split into two parts, one for the actual object O, and one for the background B beyond the perimeter of O. After phasing and retaining only the real part of I, we write for the object image I_{O}
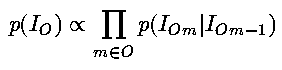 Equation 3
Equation 3
with
![p(I_{Om}|I_{Om-1})
\propto [(I_{Om} - I_{Om-1})^2 + a^2]^{-1}](marseille_abs_maths4.gif) ,
,
which has Lorentzian shape, 2a being the width at half height. For the background image we write
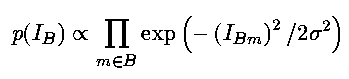 Equation 4
Equation 4
Furthermore, p(I) = p(I_{O})p(I_B). One may choose to ignore more knowledge of object boundaries. This extends Eq.3 to the entire image and obviates Eq.4.
In actual practice, we optimise the natural logarithm of p(I_S), choosing relative weights for the contributing terms \ln p(S|I), \ln p(I_O), and \ln p(I_B). This is an iterative process, based on steepest descent. Various combinations of weights can be used, depending on the application.
Ringing as a result of zero-filling of skipped less informative samples can be very substantially reduced. Furthermore, combination of the method with the partial (one-sided) scan technique [5] appeared feasible.
[2] Constable, R.T., Henkleman, R.M., Magn. Reson. Med., 14, 12 (1990)
[3] Fuderer, M., Proc. SPIE, 1137, 84 (1989)
[4] Norton, J.P., {\em An Introduction to Identification}, Academic Press, London (1986)
[5] Cuppen J., Van Est, A., Book of Abstracts, Topical Conf. on Fast Imag., Cleveland, May 15--17, 1987.